The problem
Imagine the following (completely made up ofc, no one would ever use CSV files of this size, right?) scenario:
Hello Josef! I need to get this CSV file sorted in ascending order ASAP before sending it to XXXXX. Can you help me?
The file contained 10 000 000 rows and was roughly 2.1GB in size.
Implementations
Since we are in a rush we'll try to solve this problem in the easiest possible way.
In-memory
Let's start by just reading all the lines of the file into a list and then sort it using OrderBy.
public async Task Execute(Stream source, Stream target, CancellationToken cancellationToken = default)
{
using var streamReader = new StreamReader(source);
var lines = new List<string>();
while (!streamReader.EndOfStream)
{
lines.Add(await streamReader.ReadLineAsync());
}
await using var streamWriter = new StreamWriter(target);
foreach (var line in lines.OrderBy(x => x))
{
await streamWriter.WriteLineAsync(line);
}
}
Nice. Problem solved. Let's run it.
❯ dotnet .\SortBigFileForProjectManager.dll
Sort done, took 00:01:01.4512379
We've managed to sort the file in ~1 minute, GREAT, problem solved, let's have a beer.
A couple of months later we get a new email:
Hello Josef! I need your help again, can you create a service for me where I can upload my files and sort it so I don't need to disturb you all the time? I need it ASAP, of course.
Sure, should be quick since we're using Azure, I'll just create a new Azure function. I setup a function that accepts a source file parameter (path to Azure Blob Storage) and a destination parameter. I then use the same code as above. I test it with a 10MB file, everything works perfectly, awesome, time to call it a day.
The following day I have a new URGENT email in my inbox.
JOSEF! The function is not working! When I upload this 2GB file (attached to this email) it just crashes, help me!!
That's weird? When checking the logs I can see that the following exception has been thrown:
Exception of type 'System.OutOfMemoryException' was thrown.
Great.
We are running the functions in a premium app service plan with 3.5 GB of memory. That should be enough, no?
Let's check how much memory we consume locally using the Performance Profiler.
Ouch. When sorting the 2GB file locally, we are using 5.6GB of memory. That's not good.
Whatevs, let's just pay for more memory, problem solved.
A couple of weeks later I get another email.
JOSEF!! The app is crashing again, I can't sort my 20GB file!!!! FIX IT!!!!
Sigh.
20GB and 100 000 000 lines. How much memory do we need this time?
I gave up when the memory reached 31.5GB.
We need to solve this problem in another way.
External Merge Sort
Meet External Merge Sort.
One example of external sorting is the external merge sort algorithm, which is a K-way merge algorithm. It sorts chunks that each fit in RAM, then merges the sorted chunks together.
The algorithm works something like this:
- Split the large files in multiple small files
- Sort the small files
- Merge X small files to bigger files using a K-way merge.
- Repeat step 3 until you only have 1 file left.
Just show me the code Josef
Let's break this problem down into 3 parts; splitting, sorting and merging.
The _options that you'll see throughout the code looks like this:
public class ExternalMergeSorterOptions
{
public ExternalMergeSorterOptions()
{
Split = new ExternalMergeSortSplitOptions();
Sort = new ExternalMergeSortSortOptions();
Merge = new ExternalMergeSortMergeOptions();
}
public string FileLocation { get; init; } = "c:\\temp\\files";
public ExternalMergeSortSplitOptions Split { get; init; }
public ExternalMergeSortSortOptions Sort { get; init; }
public ExternalMergeSortMergeOptions Merge { get; init; }
}
public class ExternalMergeSortSplitOptions
{
/// <summary>
/// Size of unsorted file (chunk) in bytes
/// </summary>
public int FileSize { get; init; } = 2 * 1024 * 1024;
public char NewLineSeparator { get; init; } = '\n';
public IProgress<double> ProgressHandler { get; init; }
}
public class ExternalMergeSortSortOptions
{
public IComparer<string> Comparer { get; init; } = Comparer<string>.Default;
public int InputBufferSize { get; init; } = 65536;
public int OutputBufferSize { get; init; } = 65536;
public IProgress<double> ProgressHandler { get; init; }
}
public class ExternalMergeSortMergeOptions
{
/// <summary>
/// How many files we will process per run
/// </summary>
public int FilesPerRun { get; init; } = 10;
/// <summary>
/// Buffer size (in bytes) for input StreamReaders
/// </summary>
public int InputBufferSize { get; init; } = 65536;
/// <summary>
/// Buffer size (in bytes) for output StreamWriter
/// </summary>
public int OutputBufferSize { get; init; } = 65536;
public IProgress<double> ProgressHandler { get; init; }
}
This is our Sort method right now:
public async Task Sort(Stream source, Stream target, CancellationToken cancellationToken)
{
var files = await SplitFile(source, cancellationToken);
...
}
Splitting
private async Task<IReadOnlyCollection<string>> SplitFile(
Stream sourceStream,
CancellationToken cancellationToken)
{
var fileSize = _options.Split.FileSize;
var buffer = new byte[fileSize];
var extraBuffer = new List<byte>();
var filenames = new List<string>();
await using (sourceStream)
{
var currentFile = 0L;
while (sourceStream.Position < sourceStream.Length)
{
var totalRows = 0;
var runBytesRead = 0;
while (runBytesRead < fileSize)
{
var value = sourceStream.ReadByte();
if (value == -1)
{
break;
}
var @byte = (byte)value;
buffer[runBytesRead] = @byte;
runBytesRead++;
if (@byte == _options.Split.NewLineSeparator)
{
// Count amount of rows, used for allocating a large enough array later on when sorting
totalRows++;
}
}
var extraByte = buffer[fileSize - 1];
while (extraByte != _options.Split.NewLineSeparator)
{
var flag = sourceStream.ReadByte();
if (flag == -1)
{
break;
}
extraByte = (byte)flag;
extraBuffer.Add(extraByte);
}
var filename = $"{++currentFile}.unsorted";
await using var unsortedFile = File.Create(Path.Combine(_options.FileLocation, filename));
await unsortedFile.WriteAsync(buffer, 0, runBytesRead, cancellationToken);
if (extraBuffer.Count > 0)
{
await unsortedFile.WriteAsync(extraBuffer.ToArray(), 0, extraBuffer.Count, cancellationToken);
}
if (totalRows > _maxUnsortedRows)
{
// Used for allocating a large enough array later on when sorting.
_maxUnsortedRows = totalRows;
}
filenames.Add(filename);
extraBuffer.Clear();
}
return filenames;
}
}
The above code is a modified version of this answer on Stack Overflow.
Let's break it down.
- We create a buffer (~2MB in our case).
- We start reading the bytes from the source file.
- We count all the lines in the file (more on that later, not important now)
- When we have read 2MB from the file, we stop reading. However, since we're dealing with a CSV here, we want our lines to be complete. So we continue reading until we reach a newline separator (extraBuffer).
- We then create a new file and write the buffer (and extraBuffer) to it.
- We then repeat this until all the bytes has been read from the source file.
When done with the splitting, we will have a bunch of unsorted files on disk.
Sorting
Our Sort method now looks like this:
public async Task Sort(Stream source, Stream target, CancellationToken cancellationToken)
{
var files = await SplitFile(source, cancellationToken);
// Here we create a new array that will hold the unsorted rows used in SortFiles.
_unsortedRows = new string[_maxUnsortedRows];
var sortedFiles = await SortFiles(files);
...
}
We now need to sort all the unsorted files.
private async Task<IReadOnlyList<string>> SortFiles(
IReadOnlyCollection<string> unsortedFiles)
{
var sortedFiles = new List<string>(unsortedFiles.Count);
double totalFiles = unsortedFiles.Count;
foreach (var unsortedFile in unsortedFiles)
{
var sortedFilename = unsortedFile.Replace(UnsortedFileExtension, SortedFileExtension);
var unsortedFilePath = Path.Combine(_options.FileLocation, unsortedFile);
var sortedFilePath = Path.Combine(_options.FileLocation, sortedFilename);
await SortFile(File.OpenRead(unsortedFilePath), File.OpenWrite(sortedFilePath));
File.Delete(unsortedFilePath);
sortedFiles.Add(sortedFilename);
}
return sortedFiles;
}
- We loop through all the unsorted files
- We sort it (creating a new file) using the
SortFilemethod. - We remove the unsorted one.
The SortFile method looks like this:
private async Task SortFile(Stream unsortedFile, Stream target)
{
using var streamReader = new StreamReader(unsortedFile, bufferSize: _options.Sort.InputBufferSize);
var counter = 0;
while (!streamReader.EndOfStream)
{
_unsortedRows[counter++] = await streamReader.ReadLineAsync();
}
Array.Sort(_unsortedRows, _options.Sort.Comparer);
await using var streamWriter = new StreamWriter(target, bufferSize: _options.Sort.OutputBufferSize);
foreach (var row in _unsortedRows.Where(x => x != null))
{
await streamWriter.WriteLineAsync(row);
}
Array.Clear(_unsortedRows, 0, _unsortedRows.Length);
}
- We read all the rows from the unsorted file into the _unsortedRows array created earlier.
Remember that our unsorted file is ~2MB? This is key, the size of the unsorted file controls how much memory we will allocate. - We sort the array using Array.Sort.
- We create a new sorted file.
- We clear the _unsortedRows array.
The "only" thing left to do is to merge the files.
Merging
The Sort method now looks like this:
public async Task Sort(Stream source, Stream target, CancellationToken cancellationToken)
{
var files = await SplitFile(source, cancellationToken);
_unsortedRows = new string[_maxUnsortedRows];
var sortedFiles = await SortFiles(files);
await MergeFiles(sortedFiles, target, cancellationToken);
}
The MergeFiles method looks like this:
private async Task MergeFiles(IReadOnlyList<string> sortedFiles, Stream target, CancellationToken cancellationToken)
{
var done = false;
while (!done)
{
var runSize = _options.Merge.FilesPerRun;
var finalRun = sortedFiles.Count <= runSize;
if (finalRun)
{
await Merge(sortedFiles, target, cancellationToken);
return;
}
// TODO better logic when chunking, we don't want to have 1 chunk of 10 and 1 of 1 for example, better to spread it out.
var runs = sortedFiles.Chunk(runSize);
var chunkCounter = 0;
foreach (var files in runs)
{
var outputFilename = $"{++chunkCounter}{SortedFileExtension}{TempFileExtension}";
if (files.Length == 1)
{
File.Move(GetFullPath(files.First()), GetFullPath(outputFilename.Replace(TempFileExtension, string.Empty)));
continue;
}
var outputStream = File.OpenWrite(GetFullPath(outputFilename));
await Merge(files, outputStream, cancellationToken);
File.Move(GetFullPath(outputFilename), GetFullPath(outputFilename.Replace(TempFileExtension, string.Empty)), true);
}
sortedFiles = Directory.GetFiles(_options.FileLocation, $"*{SortedFileExtension}")
.OrderBy(x =>
{
var filename = Path.GetFileNameWithoutExtension(x);
return int.Parse(filename);
})
.ToArray();
if (sortedFiles.Count > 1)
{
continue;
}
done = true;
}
}
- We create runs (chunks), in our case runSize is 10, meaning that we will merge 10 files at a time.
- We loop through each chunk, we also create 1 output stream for each chunk (the result of the merging of the 10 files).
- We call the Merge method on the 10 files (see below).
- We remove the tmp extension of the output file using File.Move.
- We check how many .sorted files that are left on disk. If more than 1, we run the loop again.
Merge method.
This is my implementation of the K-way merge mentioned earlier.
private async Task Merge(
IReadOnlyList<string> filesToMerge,
Stream outputStream,
CancellationToken cancellationToken)
{
var (streamReaders, rows) = await InitializeStreamReaders(filesToMerge);
var finishedStreamReaders = new List<int>(streamReaders.Length);
var done = false;
await using var outputWriter = new StreamWriter(outputStream, bufferSize: _options.Merge.OutputBufferSize);
while (!done)
{
rows.Sort((row1, row2) => _options.Sort.Comparer.Compare(row1.Value, row2.Value));
var valueToWrite = rows[0].Value;
var streamReaderIndex = rows[0].StreamReader;
await outputWriter.WriteLineAsync(valueToWrite.AsMemory(), cancellationToken);
if (streamReaders[streamReaderIndex].EndOfStream)
{
var indexToRemove = rows.FindIndex(x => x.StreamReader == streamReaderIndex);
rows.RemoveAt(indexToRemove);
finishedStreamReaders.Add(streamReaderIndex);
done = finishedStreamReaders.Count == streamReaders.Length;
continue;
}
var value = await streamReaders[streamReaderIndex].ReadLineAsync();
rows[0] = new Row { Value = value, StreamReader = streamReaderIndex };
}
CleanupRun(streamReaders, filesToMerge);
}
- We're creating 1 StreamReader for each file in the InitializeStreamReaders method (see below). We also read one line from each file to populate the rows list.
- We sort the rows list.
- We write the first item in the sorted list to the output stream.
- We check if there's anything left to read in the current StreamReader. If it is, we read the next line into the rows list.
- If there's nothing left in the file, we remove the row reference from the rows list.
- We repeat this logic until all StreamReaders are done.
- We cleanup the run (removing the files that we have merged).
private async Task<(StreamReader[] StreamReaders, List<Row> rows)> InitializeStreamReaders(
IReadOnlyList<string> sortedFiles)
{
var streamReaders = new StreamReader[sortedFiles.Count];
var rows = new List<Row>(sortedFiles.Count);
for (var i = 0; i < sortedFiles.Count; i++)
{
var sortedFilePath = GetFullPath(sortedFiles[i]);
var sortedFileStream = File.OpenRead(sortedFilePath);
streamReaders[i] = new StreamReader(sortedFileStream, bufferSize: _options.Merge.InputBufferSize);
var value = await streamReaders[i].ReadLineAsync();
var row = new Row
{
Value = value,
StreamReader = i
};
rows.Add(row);
}
return (streamReaders, rows);
}
private void CleanupRun(StreamReader[] streamReaders, IReadOnlyList<string> filesToMerge)
{
for (var i = 0; i < streamReaders.Length; i++)
{
streamReaders[i].Dispose();
// RENAME BEFORE DELETION SINCE DELETION OF LARGE FILES CAN TAKE SOME TIME
// WE DONT WANT TO CLASH WHEN WRITING NEW FILES.
var temporaryFilename = $"{filesToMerge[i]}.removal";
File.Move(GetFullPath(filesToMerge[i]), GetFullPath(temporaryFilename));
File.Delete(GetFullPath(temporaryFilename));
}
}
private string GetFullPath(string filename)
{
return Path.Combine(_options.FileLocation, filename);
}
Benchmarks
I've profiled the memory usage using dotMemory from Jetbrains. As you can see, the algorithm uses the same amount of memory (~50MB) regardless of the file size.
1000 rows ~ 209KB
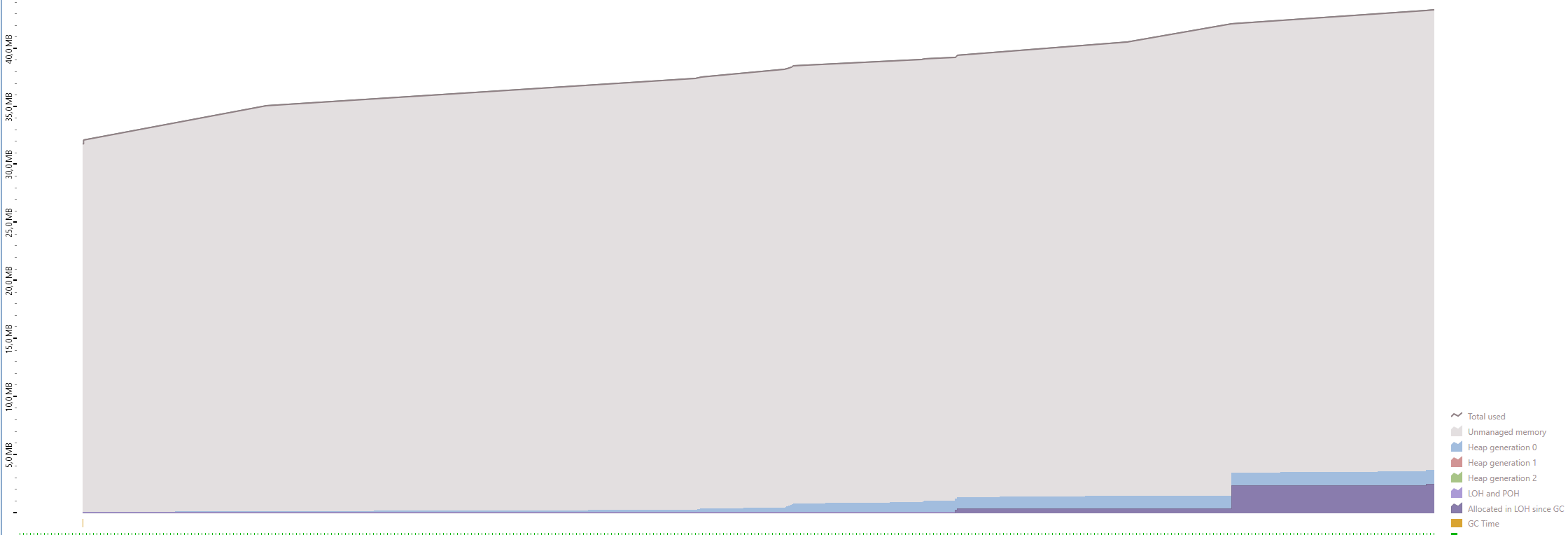
10 000 rows ~ 2.1MB
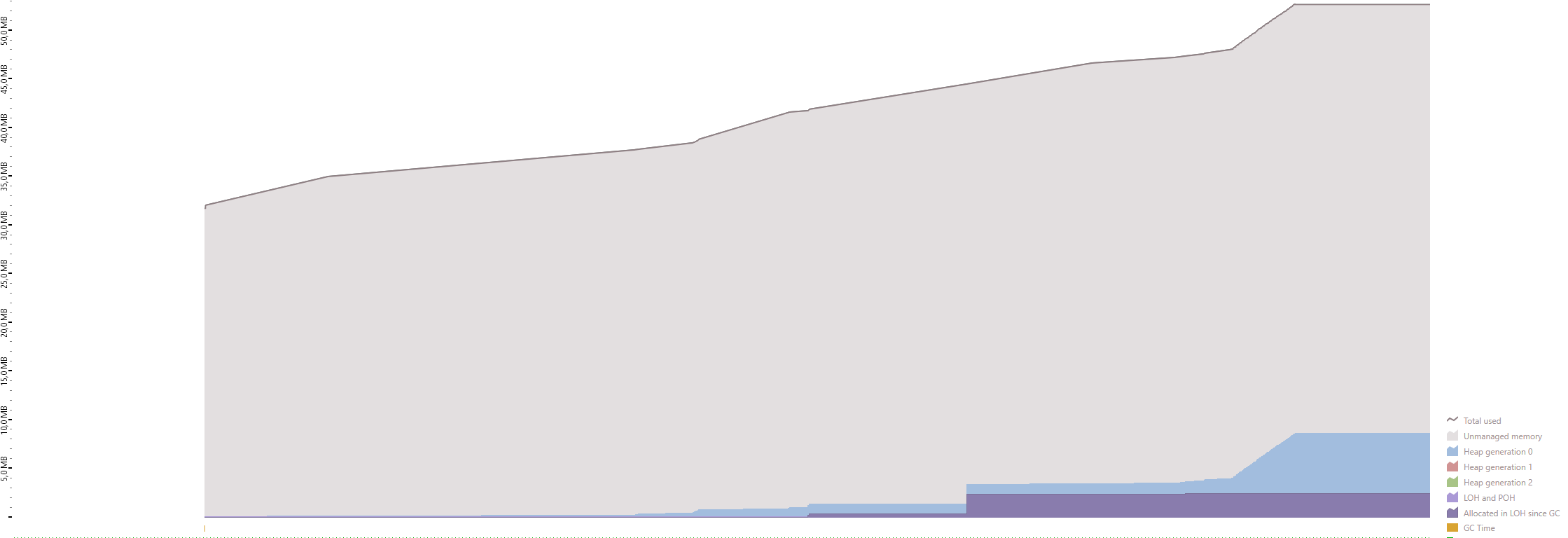
100 000 rows ~ 21MB
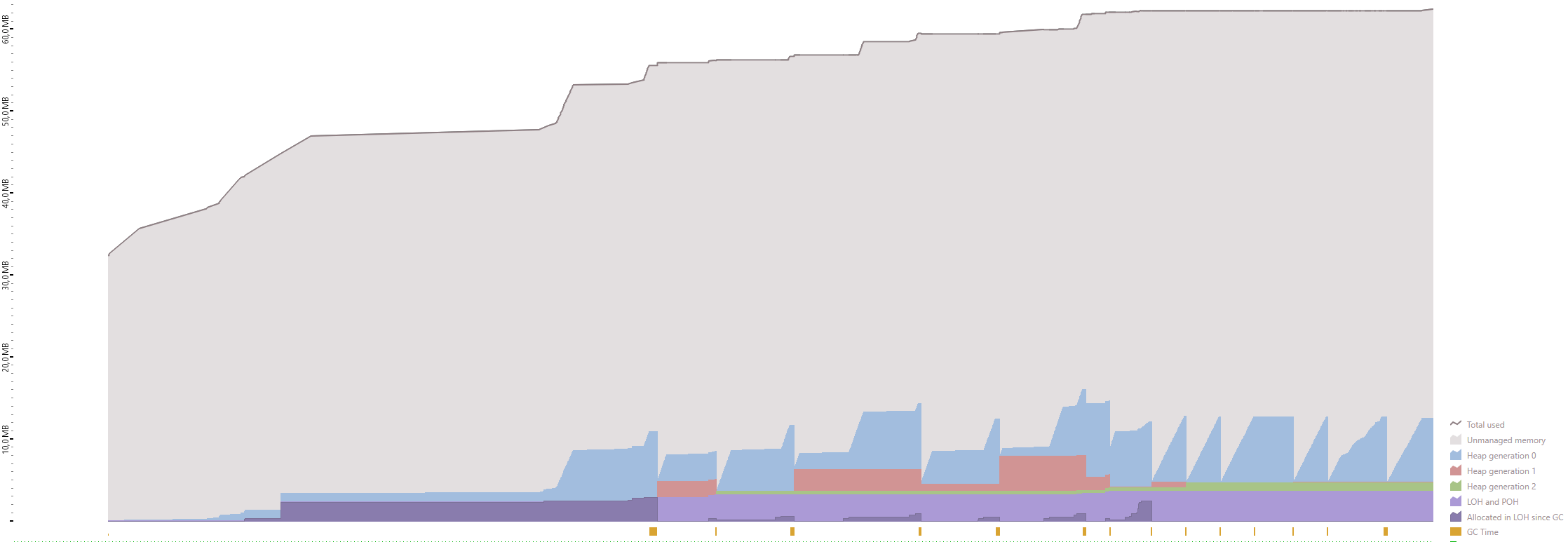
1 000 000 rows ~ 211MB
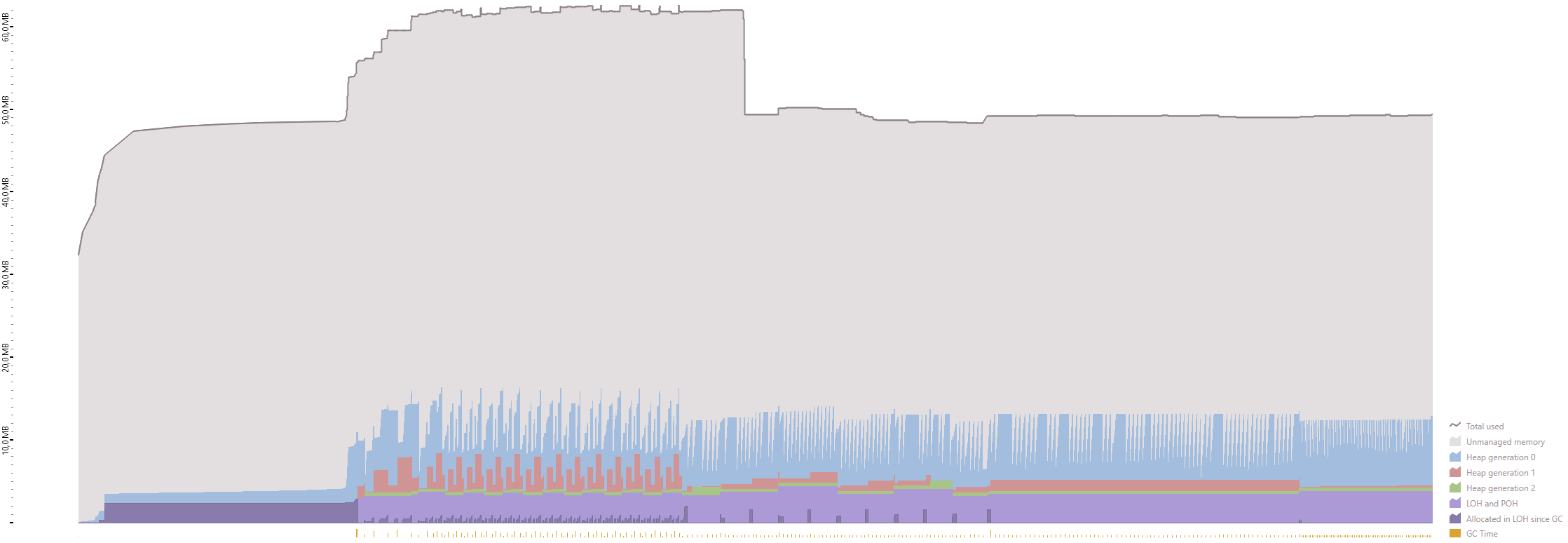
10 000 000 rows ~ 2.03GB
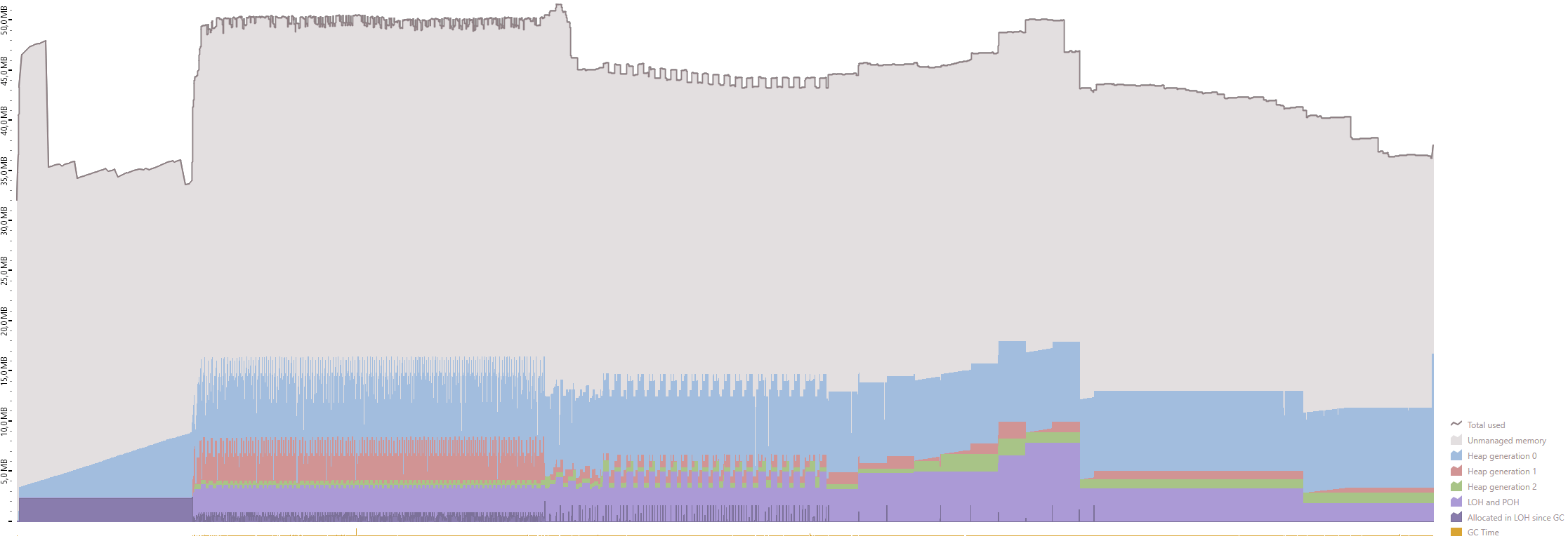
100 000 000 rows ~ 21.32GB
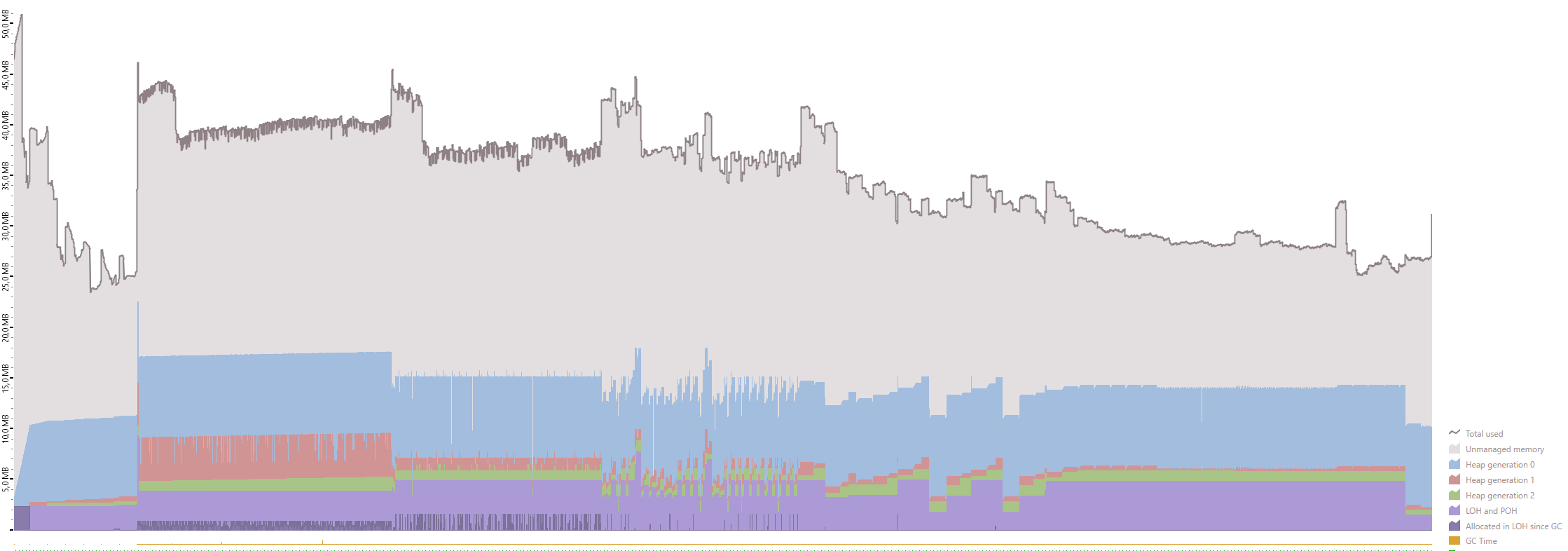
Since this algorithm uses a lot of I/O, it's important to use fast storage. I recommend using a SSD if possible.
